
자율 주행 기술을 위해서는 위의 그림처럼 승용차, 트럭, 사람, 표지판 내용을 인식할 뿐만 아니라 움직이는 차량을 계속적으로 추적하여 속도, 이동할 방향을 확인한 후, 해당 차의 주행을 판단해야 한다.
그럼 이 기능을 구현하기 위해서는 어떤 기술이 필요할까?
아주 기초적인 단계부터 다지고 가면 크게 3가지로 말할 수 있다.
1. Classification
2. Object Detection
3. Image Segmentation
위 순서대로 기술을 고도화 시킨다고도 볼 수 있다.
혹은 적용하는 어플리케이션 특성에 따라 하나는 생략하고 두가지만 접목시켜 구현하기도 한다.

- Classification : Single object에 대해서 object의 클래스를 분류하는 문제이다.
- Classification + Localization : Single object에 대해서 object의 위치를 bounding box로 찾고 (Localization) +
클래스를 분류하는 문제이다. (Classification) - Object Detection : Multiple objects에서 각각의 object에 대해 Classification + Localization을 수행하는 것이다.
- Image Segmentation : Object Detection과 유사하지만, 다른 점은 object의 위치를 bounding box가 아닌 실제 edge로 찾는 것이다. (Image Segmentation은 Image Segmentation의 일종.)
여태까지 올린 포스팅에서는 대부분 single object를 분류하는 'classification'에 대해 다루었다.
2021.07.11 - [AI | 딥러닝/Concept] - [딥러닝 모델] CNN (Convolutional Neural Network) 설명
2021.08.01 - [AI | 딥러닝/Concept] - [AI/딥러닝] CNN Network layer 모델들 (AlexNet, GoogLeNet, ResNet)
하지만 생각해보면 우리가 적용할 어플리케이션에는 하나의 물체만 탐지하는 것을 원하지 않는다. 한 장의 이미지에서 최대한 많은 갯수의 물체를 탐지하여 빠른 시간 안에 상황을 판단해야 한다.
그렇기에 레벨 5의 자율 주행 기술을 구현하기 위해서는 Image Segmentation 단계까지 물체를 detect 할 수 있어야 한다.
그럼 단계별로 어떤 Layer들이 구성되는 지 하나씩 개념을 짚고 가보자.
Classification
한 이미지에 있는 물체가 무엇인지를 알아내야 한다.
Layer들을 쌓아가면서 그 물체의 특징을 점점 부각시키는 training을 한다.
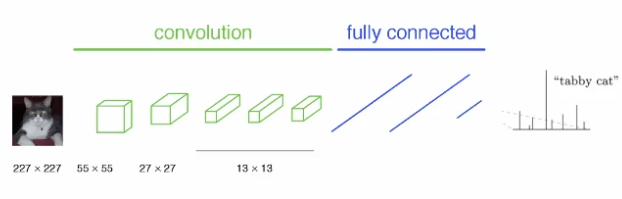
그 방식은 filter 역할을 하는 convolution layer과 단위를 down시키는 pooling layer를 번갈아가며 사용하여 이미지의 feature를 추출하고 fully connected layer를 통해 classification을 진행한다.
그렇게 해서 Output으로 class들의 정확도를 출력한다. N개의 class에서 정답일 확률들을 나열하는 것이다.
대표적으로 CNN 네트워크가 쓰이며 구체적인 예시로 GoogLeNet, ResNet 등이 있다.
FCN (Fully Convolutional Neural network)
그러다 연구자가 문득 이런 생각을 했다.
fully connected layer 대신 다 convolution layer로 돌리면 어떻게 될까?
이 방식에서 fully connected layer 대신 convolution layer를 사용한다.
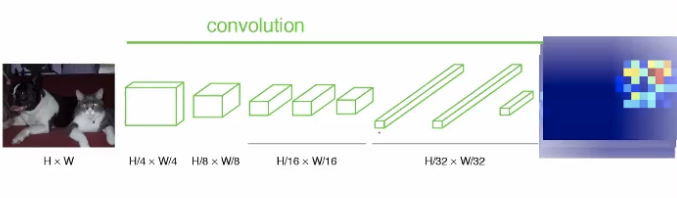
처음부터 끝까지 convolution layer만 사용하기 때문에 입력 사이즈를 down 시켜주는 layer가 없다. 그래서 입력 사이즈가 커지면 출력 사이즈도 커진다. 이건 CNN과 달리 output이 class의 정확도가 아닌 image 형태로 출력되고 input 이미지에서 원하는 특징이 두드러진 위치를 위의 오른쪽 이미지처럼 강조시킨다.
위의 이미지는 오른쪽엔 개, 왼쪽엔 고양이가 있는 input 이미지를 넣고 '고양이' 찾기를 위한 FCN을 적용 후, 고양이가 위치한 부분에 강조된 output 이미지를 얻었다.
이걸 FCN (Fully Convolutional Neural network) 라고 한다.
각 위치별로 어떤 물체가 있는 지 알 수 있더라.
Object Detection
Object detection은 bounding box로 input 이미지에 있는 모든 물체를 찾는 것이고 더불어 bounding box의 중심과 물체의 중심이 일치할 수록 성능이 좋은 것이다.
성능 지표
object detection 성능을 나타내는 파라미터는 두 가지가 있다.
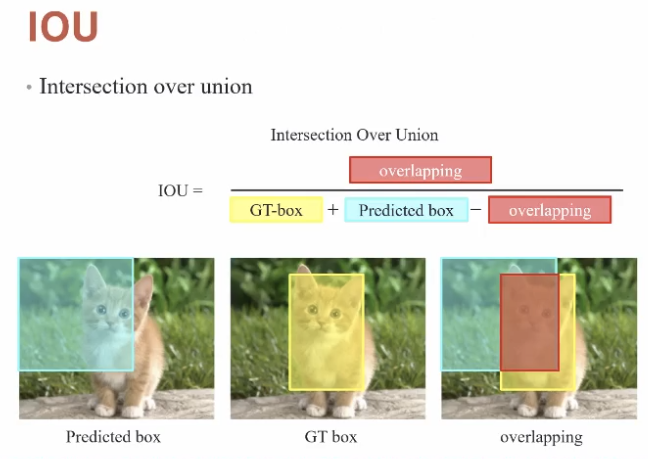
하나는 IoU (Intersection over Union).
object detection는 물체가 어디 있는 지 localization을 먼저 하기 때문에 내가 찾은 물체의 bounding box 정확도가 중요하다. 이 값은 실제 물체를 중심을 두고 있는 bounding box와의 겹치는 정도로 판단한다.
이는 bounding box의 중심과 물체의 중심이 얼마나 일치하는 지를 나타내는 지표이다.
이 값은 0.7 정도만 되도 높은 수준이다.
다른 하나는 mAP (mean Average Precision).
이는 bounding box로 input 이미지에 있는 물체를 얼마나 높은 정확도로 찾는 지에 대한 지표이다.

위의 표에서는 결과 값으로 Precision과 Accuracy를 출력한다.
Target은 실제 값의 결과로 총 100명의 사람 중에 병에 걸린 사람(Positive)가 15명, 병에 안 걸린 사람(Negative)가 85명이다.
하지만 딥러닝 모델은 Positive를 50명, Negative를 50명으로 봤다.
여기서 실제 Target 값과 예측 Model 값이 일치하는 값은 빨간 박스의 10과 45 이다.
'Precision'은 예측 model에서 실제 positive를 맞춘 확률이고 'Accuracy'는 전체 데이터에서 실제 positive와 negative를 맞춘 확률이다.
그리고 'Recall' 은 positive 판정에서 얼마나 정확하게 실제 Positive를 맞췄는 지에 대한 확률이다.
여기서 중요한 개념이 하나 있는데 positive와 negative를 구분하는 요소에는 'threshold'가 있다. 사용자가 설정하는 threshold 값에 의해 positive와 negative가 정해진다. 그래서 만약 threshold를 증가시키면 recall 값이 증가하고 precision 값이 감소한다. 대체적으로 recall 값과 precision 값은 trade-off 관계라는 것을 알 수 있다.
그래서 물체를 얼마나 높은 정확도로 찾는 지를 알기 위해서 recall 값을 고정한 상태에서 precision을 비교해야 한다.
mAP는 recall별로 precision 값을 구한 후, 평균을 내서 하나의 성능 값으로 나타내겠다는 뜻이다.

여기까지 성능 지표에 대한 대표적인 2가지 파라미터 IOU와 mAP에 대해 알아보았다.
다음 포스팅에서는 object detection을 구성하는 2가지 분류 1-stage detector와 2-stage detector에 대해 알아보며 R-CNN, Faster R-CNN, YOLO, SSD에 대해 알아보겠다.

다음 시리즈는 아래 링크를 참고하면 된다:)
위 글이 도움이 되셨다면, 아래 하트를 눌러주세요↓
감사합니다 \( ˆoˆ )/




댓글