진정한 딥러닝을 위한 3가지 분류 마지막 시리즈 이다.
Classification과 Object detection에 관한 내용은 아래 1탄과 2탄을 참고하면 좋다.
이번 포스팅에서는 마지막 남은 한 가지 'Image segmentation'에 대해 알아볼 예정이다.
Segmentation 정의
Segmentation은 pixel-level(혹은 pixel-wise)로 classification을 수행하는 것을 말한다. 아래 그림처럼 말이다.

이미지의 pixel 별로 1번에서 5번까지 object를 각각 구별하였다.
Segmentation 종류
Image segmentation에는 총 3가지 종류가 있다.
- Semantic segmentation
- Instance segmentation
- Panoptic segmentation
말로 정의하기 전에 먼저 그림으로 확인해보자.

위 그림은 원본 이미지 (a)를 가지고 각각 semantic segmentation, instance segmentation, panoptic segmentation을 수행할 결과를 나타낸다. 하나씩 특징을 확인하면 다음과 같다.
- Semantic segmenation: Object 별로 구분한다. 그래서 동일한 object는 같은 색상으로 표현되고 한 번에 Masking을 수행한다. 그리고 주변 배경을 포함하여 모든 pixel을 레이블한다. FCN이 가장 대표적인 기법이다.
- Instance segmentation: Sematic과 비교했을 때 각각 object들이 개별로 취급된다. 개별 Object 별로 Masking을 수행한다. Mask RCNN이 가장 대표적인 기법이다.
- Panoptic segmentation: 위 두 가지 방법인 segmenation과 instance를 합친 것이다. 모든 pixel에 대해 레이블하면서 각각의 object 별로 개별 masking을 수행한다. DeepLab이 가장 대표적인 기법이다.
Panoptic segmentation - DeepLab
그래서 DeepLab을 이용한 panoptic segmentation 다이어그램을 그리면 다음과 같다.
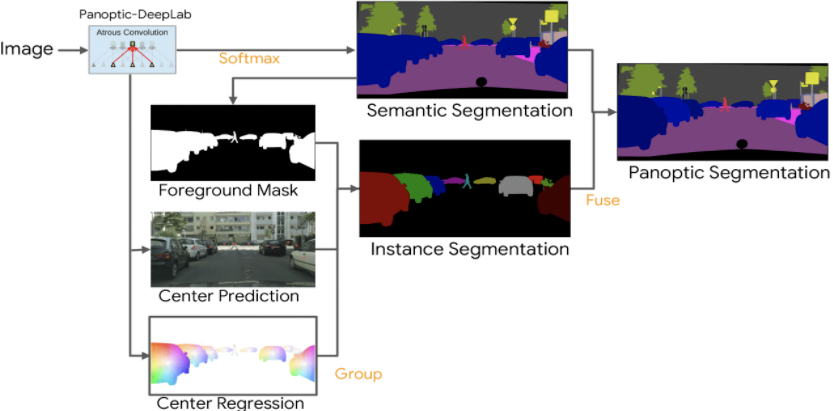
먼저 위에서 언급했듯이 panoptic segmentation은 semantic segmentation과 instance segmenation의 합으로 만들어진다. 이 뜻은 output의 채널 수와 정확하게 맞아 떨어진다.
더 빠른 이해를 위해 예를 들면 다음과 같다.
Input으로 W x H x 3 개 채널 이미지가 들어간다. (여기서 3은 color 여서)
그리고 결론부터 말하면 Output은 W' x H' x ((class 갯수) + 3) 으로 나온다.
W'와 H' 은 convolution으로 변환되는 값이므로 생략하고 여기서 주목할 점은 기존 3에서 늘어난 (class 갯수) + 3 이다.
원본 image에서 semantic segmentation 결과를 얻을 때 내가 구별하고자 하는 object 종류에 따라 class 갯수가 달라진다. 그리고 나머지 3개의 채널은 1개는 center prediction에 다른 2개는 center regression에 사용한다. 이 3개의 채널을 이용하여 instance segmentation을 가능하게 하는 것이다. 그렇게 우린 semantic segmentation과 instance segmentation 결과를 얻을 수 있고 이 들의 채널 수를 더하면 output의 panoptic segmentation 결과가 나오는 것이다.
그럼 center prediction은 무엇일까?
나는(특정 pixel) 내가 속한 instance의 중심인가 를 판단하는 것이다. Boolean 방식으로 맞으면 1, 틀리면 0의 결과를 내놓는다.
그 다음 center regression은 2차원 벡터를 나타낸다. 나는(특정 pixel) 내가 속한 instance와 벡터가 어떻게 되는 지 를 판단하는 것이다.
그래서 위의 그림을 다시 설명해보면
원본 image에 'atrous convolution'을 적용하여 semantic segmentation 결과를 얻는다. 그런 다음 'softmax'를 적용하여 차라는 object만 masking 되는 foreground mask 결과를 얻는다. 그리고 이 mask 대상 중에서 center들을 얻기 위해 'non-max suppression'을 진행한다. 물체의 진짜 중심에만 하나의 점이 찍힐 것이다(center prediction). 그러고 그 중심과 나(특정 pixel)과의 벡터 관계를 나타내어 가장 가까운 물체를 label한다(center regression). 이 결과를 통해 얻은 걸로 instance segmentation을 만든다.
그리고 semantic segmentation 과 instance segmentation 결과를 합치면 panoptic segmentation이 되는 것이다.
이 다이어그램이 DeepLab을 이용한 panoptic segmentation 이다.
이번 포스팅을 마지막으로 전반적인 딥러닝을 위한 3가지 분류를 알아보았다.
너무나 간략히 알아본 것이라 각 분류에 적용되는 세부 기술들은 추후에 하나씩 깊게 짚어볼 예정이다.
다시 한번 1탄의 내용을 복기하자면,
자율 주행 기술을 위해서는 위의 그림처럼 승용차, 트럭, 사람, 표지판 내용을 인식할 뿐만 아니라 움직이는 차량을 계속적으로 추적하여 속도, 이동할 방향을 확인한 후, 해당 차의 주행을 판단해야 한다.
그럼 이 기능을 구현하기 위해서는 어떤 기술이 필요할까?
아주 기초적인 단계부터 다지고 가면 크게 3가지로 말할 수 있다.
1. Classification
2. Object Detection
3. Image Segmentation
위 순서대로 기술을 고도화 시킨다고도 볼 수 있다.
혹은 적용하는 어플리케이션 특성에 따라 하나는 생략하고 두 가지만 접목시켜 구현하기도 한다.
위 글이 도움이 되셨다면, 아래 하트를 눌러주세요↓
감사합니다 \( ˆoˆ )/
'AI | 딥러닝 > Concept' 카테고리의 다른 글
| [Microsoft DeepSpeed] ZeRO paper series 리뷰 (4) | 2024.10.18 |
|---|---|
| [뉴스 스크랩] 점점 커져가는 초거대 NLP AI 모델들의 크기 (0) | 2022.03.15 |
| [AI/딥러닝] 진정한 딥러닝을 위한 3가지 분류 (Classification, Object Detection, Image Segmentation) 2탄 (0) | 2021.09.09 |
| [AI/딥러닝] 진정한 딥러닝을 위한 3가지 분류 (Classification, Object Detection, Image Segmentation) 1탄 (1) | 2021.08.31 |
| [AI/머신 러닝] 머신러닝의 종류 (Supervised, Unsupervised, Reinforcement) (0) | 2021.08.24 |




댓글