이 포스팅을 읽기 전 classification과 object detection의 성능 지표에 대해 설명한 아래 포스팅을 먼저 읽고 오면 도움이 된다.
[AI/딥러닝] 진정한 딥러닝을 위한 3가지 분류 (Classification, Object Detection, Image Segmentation) 1탄
자율 주행 기술을 위해서는 위의 그림처럼 승용차, 트럭, 사람, 표지판 내용을 인식할 뿐만 아니라 움직이는 차량을 계속적으로 추적하여 속도, 이동할 방향을 확인한 후, 해당 차의 주행을 판단
rubber-tree.tistory.com
Object detection의 2가지 방식
object detection는 아래 맵과 같이 크게 2 파트로 나뉜다.
One-stage detector(approaches)와 two-stage detector(approaches).

둘의 가장 큰 차이점은 Regional Proposal과 Classification이 순차적으로 이루어지나? (-> Two-stage detector)
혹은 동시에 이루어지나? (-> One-stage detector) 이다.
Regional Proposal 이란? (aka. RPN)
기존에는 이미지에서 object detection을 위해 sliding window방식을 이용했었는데 Sliding window 방식의 비효율성을 개선하기 위해 '물체가 있을 만한' 영역을 빠르게 찾아내는 알고리즘이 region proposal 이다. Image Crop과 Warp을 적용하여 2000개의 Region 영역을 Proposal 한다. 즉, regional proposal은 object의 위치를 찾는 localization 문제이다.
대표적으로 Selective search, Edge boxes들이 있다. Selective Search기법이란 Region Proposal의 대표 방법으로써 원본 이미지로부터 최초 Segmentation을 수행하고 이를 통해 후보 Object를 추출하는 기법이다. 이를 통해 빠른 Detection과 높은 Recall 예측 성능을 동시에 만족하는 Algorithm 기법이다. 이는 Color, 무늬(Texture), 크기(Size), 형태(Shape)에 따라 유사한 Region을 계층적 그룹핑 방법으로 계산하는 기법이다.
먼저 Two-stage detector에 대해 얘기해보면,
2-stage detector
Two-stage detector는 Regional Proposal과 Classification이 순차적으로 이루어진다.

1) Image Crop과 Warp을 적용하여 2000개의 Region 영역을 Proposal 한다. (Regional Proposal)
2) 추출된 2000개의 Region에 대해 각각 classification을 진행한다.
아래 그림을 보면 좀더 이해하기 쉽다.

위 그림은 2-stage detector의 동작과정 인데 Selective search, Region proposal network와 같은 알고리즘 및 네트워크를 통해 object가 있을만한 영역을 우선 뽑아낸다. 이 영역을 RoI(Region of Interest)라고 하며, 이런 영역들을 우선 뽑아내고 나면 각 영역들을 convolution network를 통해 classification, box regression(localization)을 수행한다.
ROI 영역이 위 그림처럼 딱 개만 잡아서 4개가 추출되면 좋겠지만 위의 설명처럼 2000개가 잡히고 각각 classification을 진행한다.
그렇기 때문에 1-stage detector보다 출력 결과가 정확하다는 장점이 있지만 속도가 굉장히 느리다.
그럼 1-stage detector는 어떨까?
1-stage detector
One-stage detector는 Regional Proposal과 Classification이 동시에 이루어진다.
Feature extraction에 해당하는 Conv layers에서 두 가지가 동시에 이루어진다.
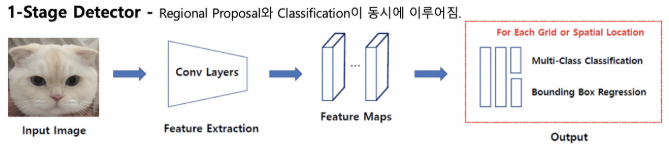
여기는 ROI 영역을 추출하는 것이 아니라 Anchor box라는 개념을 사용한다.
Anchor box란?
미리 정의된 형태를 가진 경계박스 수를 ‘앵커 박스(Anchor Boxes)’라고 한다. 앵커 박스는 K-평균 알고리즘에 의한 데이터로부터 생성되며, 데이터 세트의 객체 크기와 형태에 대한 사전 정보를 확보한다. 각각의 앵커는 각기 다른 크기와 형태의 객체를 탐지하도록 설계되어 있다.

1) 먼저 input image를 n x n Grid 형식으로 쪼갠다. (아래 그림에선 13 x 13 으로)
2) 각 Grid의 Cell이 n개의 Object에 대한 Detection을 수행한다. (1개의 Cell에서 여러 개의 Anchor를 통해 개별 Cell에서 여러 개의 Object Detection이 가능하다.)
3) 각 Grid Cell이 2개의 Bounding Box후보를 기반으로 Object의 Bounding Box를 예측한다.
4) 그리고 하나씩 찾으면서 동시에 classification이 이루어진다.
2-stage detector는 input 이미지의 전체 영역에서 정확한 물체의 위치에 ROI를 설정하기 위해 고군 분투한다면,
1-stage detector는 정해진 빙고판 안에서 최대한 물체가 있는 위치를 잡는다.
그러니 1-stage detector가 2-stage detector보다 정확도가 떨어진다고 볼 수 있다. 대신 1-stage detector의 grid를 더 잘게 쪼갠다면 그 정확도는 점점 올라갈 수 있다.
1-stage detector와 2-stage detector의 대표적인 예시로는 아래 네트워크만 알고 있어도 충분하다. 이전 네트워크의 단점을 하나씩 수정하여 가장 보완된 최신 모델이기 때문이다.
- 2-stage detector: Faster R-CNN
- 1-stage detector: YOLO v3, SSD
이들의 알고리즘에 대해서 알고 싶다면 아래 글을 참고하면 좋다.
2021.08.01 - [AI | 딥러닝/Concept] - [AI/딥러닝] 객체 검출(Object Detection) 모델의 종류 R-CNN, YOLO, SSD
[AI/딥러닝] 객체 검출(Object Detection) 모델의 종류 R-CNN, YOLO, SSD
지금까지 딥러닝의 모델과 그 중에서 CNN의 세부 모델까지 알아보았습니다. 2021.07.10 - [SW programming/Computer Vision] - AI, 머신러닝, 딥러닝 이란? 그리고 딥러닝 모델 종류 2021.07.11 - [SW programming..
rubber-tree.tistory.com
다음 포스팅에서는 마지막 분류인 'Image Segmentation'에 대해 알아보겠다.
위 글이 도움이 되셨다면, 아래 하트를 눌러주세요↓
감사합니다 \( ˆoˆ )/
'AI | 딥러닝 > Concept' 카테고리의 다른 글
| [뉴스 스크랩] 점점 커져가는 초거대 NLP AI 모델들의 크기 (0) | 2022.03.15 |
|---|---|
| [AI/딥러닝] 진정한 딥러닝을 위한 3가지 분류 (Classification, Object Detection, Image Segmentation) 3탄 (0) | 2021.09.19 |
| [AI/딥러닝] 진정한 딥러닝을 위한 3가지 분류 (Classification, Object Detection, Image Segmentation) 1탄 (1) | 2021.08.31 |
| [AI/머신 러닝] 머신러닝의 종류 (Supervised, Unsupervised, Reinforcement) (0) | 2021.08.24 |
| [AI/딥러닝] On-device AI를 위해 하드웨어 컴퓨팅이 가야할 길 (0) | 2021.08.14 |




댓글